上期内容回顾上个专题我们介绍了R语言的数据导入,将R语言导入几种常用软件数据的方式介绍了给大家,下面做个基本回顾。
键盘输入数据:创建数据框,调用fix( )函数
TXT数据导入:调用read.table( )函数
Excel数据导入:转换为csv文件,调用read.csv( )函数
SPSS数据导入:调用Hmisc包中的spss.get( )函数
SAS数据导入:两种方法:一种针对bdat格式文件,调用sas7bdat包中的read.sas7bdat( )函数;另一种是使用SAS文件将数据导出为csv文件,再使用read.csv( )函数。
Stata数据导入:调用foreign包中的read.dta( )函数
netCDF数据导入:使用open.ncdf( )、get.var.ncdf( )函数
温馨提示:如果你对上述所讲的内容还有些陌生,就先不要急着阅读下文的内容,先打开R动手练习练习再来学习吧~
本期内容导读导入数据后就可以着手对数据进行分析啦。描述性统计就是对导入后的数据进行一个简单的统计分析,即用数值对每个变量的分布进行描述,从而对数据分布情况进行简单了解。对于这部分内容,我们在这里将会主要介绍四个函数:summary( )、describe( )、aggregate( )、sapply( )。
示例数据:
如下图所示,包含四个变量:不同类型的糖尿病患者低、高脂蛋白的胆固醇含量(LDL、HDL)及载脂蛋白B(ApoB)的测量结果(单位:mg/dl)
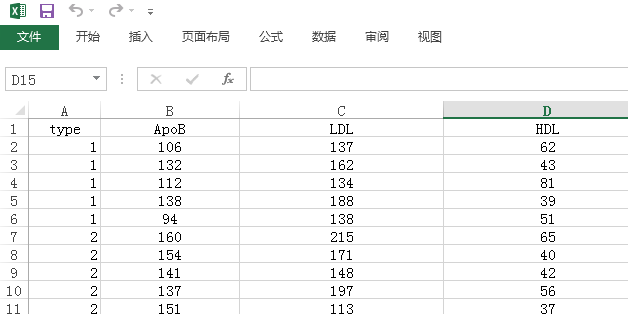
1summary( )函数用途:summary( )函数提供了最小值、最大值、上下四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计。示例如下图:
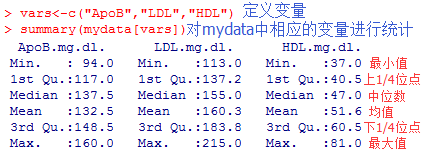
2describe( )函数用途:describe( )函数对数据描述的更加具体,其可返回变量和观测的数量、缺失值和唯一值的数目、平均值、分位数,以及五个最大的值和五个最小的值。
温馨提示:使用该函数需要提前安装并加载Hmisc包。
3aggregate( )函数用途:用来对数据进行分类汇总,比如对不同类型病人分别计算其三个观测指标的平均值。
函数调用形式:
aggregate(data,by,Fun)
参数解释:
参数data 为待分析的数据对象,by 是由一个变量名组成的列表,这些变量的作用是对数据进行分组,而Fun 则是对分组后的数据计算描述性统计量的函数。
注意:在使用aggregate( )函数的时候,by 中的变量必须在一个列表中(即使只有一个变量)。你可以在列表中为各个组取一个自定义的名称,例by=list(type=mydata$type)。指定的函数可为任意的内建或自编函数,这就为这个函数赋予了强大的力量。
4sapply( )函数
到了这里,你可能会想到R中现有的函数对数据的描述性统计方法都是预先设定好的,例如summary( )中的分位数,describe( )中的频数统计等。有些时候,我们会想要自定义统计结果,比如计算每个观测指标的均值和方差,这时候使用以上函数,再将结果提取出不免有些麻烦。此时,sapply( )函数就能够帮到你。

拓展延伸
下期预告
本期的描述性统计分析就先到这里啦,对上述内容还希望大家多多动手练习。本周五会接着介绍R的基本数据管理及数据预处理,欢迎大家围观!!!


 发表于 2015-1-1 15:57:32
发表于 2015-1-1 15:57:32